Ecco il Manuale Definitivo per Tutti!

Che cosa succederebbe se potessi avere la tua intelligenza artificiale, 100% locale, senza internet e completamente privata? Questo guida ti mostra come far girare un LLM sul tuo PC, anche se non sei un esperto.
Sapevi che è possibile avere il tuo personale ChatGPT che gira direttamente sul tuo computer, senza dipendere da un servizio online? I grandi modelli di linguaggio, o LLM (Large Language Models), non sono più riservati ai giganti del cloud. Oggi, con un PC o Mac adeguato e alcuni suggerimenti, puoi installarli a casa tua.
Perché? Per mantenere i tuoi dati privati, evitare abbonamenti costosi o semplicemente per modificare un’IA a tuo piacimento. In questa guida, ti spieghiamo tutto, passo dopo passo.
Che cos’è un LLM? È come ChatGPT?
Un LLM, o Large Language Model (grande modello di linguaggio), è un’IA addestrata su enormi volumi di testi per comprendere e generare il linguaggio umano. In pratica, ciò significa che può discutere, rispondere a domande, scrivere testi o persino codificare, un po’ come un super assistente virtuale. Il principio è che gli diamo un’istruzione (un prompt) e lui utilizza i suoi miliardi di parametri – una sorta di connessioni apprese – per fornire una risposta coerente. ChatGPT è un esempio famoso di LLM, creato da OpenAI, ma ce ne sono molti altri, come LLaMA, Mistral o DeepSeek, spesso gratuiti e open-source.
Per approfondire
Che cos’è un LLM? Come funzionano i motori di ChatGPT, Gemini e altri?
Quindi, è esattamente come ChatGPT? Non esattamente. ChatGPT è una versione ultra-ottimizzata di un LLM, con guardrails (confini) per restare sicuro e un’interfaccia pronta nel cloud. Gli LLM che possiamo installare localmente, invece, sono spesso più grezzi: dipendono da come li configuri e dalla tua attrezzatura (PC o Mac). Possono essere anche altrettanto potenti, se non personalizzabili, e puoi addestrarli sui tuoi stessi testi, ma non sempre hanno lo stesso aspetto o la stessa facilità di accesso di ChatGPT. Puoi anche avere un’interfaccia tanto intuitiva quanto ChatGPT, tutto dipende dalle tue necessità.
Perché installare un LLM a casa?
Iniziamo dal vantaggio principale: la privacy. Quando utilizzi un’IA online, le tue conversazioni vengono spesso inviate a server lontani. Diverse interruzioni di servizi come ChatGPT, Grok o Gemini si sono verificate, questi servizi non sono affatto 100% disponibili e, soprattutto, 100% sicuri.

Un’interruzione nel 2023 presso OpenAI ha dimostrato che gli storici degli utenti possono trapelare accidentalmente – non è molto rassicurante se stai trattando dati sensibili. Con un LLM locale, tutto rimane sul tuo computer. Nulla esce dal tuo dispositivo, punto finale. Questo è un argomento convincente per le aziende o per coloro che sono molto attenti alla privacy.
Poi c’è l’autonomia. Non hai bisogno di internet per far funzionare la tua IA. Sia che tu sia in campagna o in aereo, risponderà presente. E per quanto riguarda la velocità, se la tua macchina è ben equipaggiata, eviterai i rallentamenti a causa dei viaggi di andata e ritorno del network che talvolta riducono la velocità dei servizi cloud. Come vedrai, anche su un MacBook M1 ben ottimizzato, un LLM locale supera un PC classico in reattività. Aggiungi a questo l’assenza di guasti del server o di quote imposte da un provider, e sei libero come l’aria.
E per quanto riguarda i costi? A prima vista, è necessario investire un po’ di soldi in attrezzature (ci torneremo più avanti), ma a lungo termine, è spesso più conveniente che pagare un’API cloud per parola generata. Niente fatture a sorpresa o aumenti di prezzo inaspettati. Una volta che il tuo PC o GPU è pronto, la tua IA ti costa solo qualche watt di elettricità.
Infine, il meglio del meglio: puoi personalizzare il tuo modello. Cambiare i suoi parametri, addestrarlo sui tuoi testi e addirittura collegarlo alle tue applicazioni personali: con un LLM locale, sei tu al comando.
Ma attenzione, non è magia. Ti serve una macchina affidabile, e l’installazione può intimidire i principianti. I modelli più enormi, quelli con centinaia di miliardi di parametri, sono ancora al di fuori della portata dei computer classici – qui si parla di supercomputer. Detto ciò, per usi comuni (chat, scrittura, codifica), i modelli open-source più leggeri funzionano ampiamente.
Quali modelli scegliere?
Ci sono molte opzioni per i modelli. Prendiamo ad esempio DeepSeek R1. Uscito all’inizio del 2025, questo modello open-source ha avuto un grande successo con le sue versioni da 7 miliardi (7B) e 67 miliardi (67B) di parametri. È molto efficace in ragionamento e generazione di codice, e la sua versione 7B funziona perfettamente su un PC adeguato. Un altro grande successo è LLaMA 2, creato da Meta. Disponibile in 7B, 13B e 70B, è molto popolare grazie alla sua flessibilità e alla licenza gratuita – anche per usi professionali. Il 7B è perfetto per i principianti, il 70B richiede un hardware potente.
Esiste anche Mistral 7B, modello francese. Con i suoi 7,3 miliardi di parametri, supera modelli due volte più grandi in alcuni test, mantenendo una leggerezza. Ideale se hai una scheda grafica con 8 GB di memoria video (VRAM).
Mistral Small è uno dei più recenti LLM di Mistral AI, la nota startup francese. Questo modello, uscito all’inizio del 2025 nella sua versione “Small 3.1”, è progettato per essere leggero ed efficace, con 24 miliardi di parametri (24B). L’idea è che sia abbastanza potente per competere con modelli come GPT-4o Mini. In pratica, può funzionare su un PC o un Mac senza svuotarti le tasche in hardware, a patto di avere un po’ di memoria disponibile.
Anche Google ha il suo LLM open-source, chiamato Gemma, una famiglia di modelli ottimizzati per l’esecuzione locale. Gemma 2B e Gemma 7B sono progettati per funzionare su macchine modeste, comprese Mac M1/M2/M3/M4 e PC con GPU RTX.
La lista degli LLM open-source sta crescendo ogni mese. Vale la pena menzionare iniziative come GPT4All, che raccoglie decine di modelli pronti all’uso tramite un’interfaccia unificata. GPT4All supporta più di 1000 modelli open-source popolari, tra cui DeepSeek R1, LLaMA, Mistral, Vicuna, Nous-Hermes e molti altri.
In sintesi, hai una vasta scelta: dal piccolo modello ultra-leggero da eseguire su CPU fino al grande modello quasi equivalente a ChatGPT se hai l’hardware giusto. L’importante è selezionare quello che corrisponde alle tue necessità (lingua, tipo di compito, prestazioni) e al tuo hardware.
Per quanto riguarda l’hardware, non hai bisogno di un supercomputer, anche se questi stanno diventando sempre più personali, con quello che Nvidia e AMD lanciano quest’anno… e persino un Mac Studio.
Per approfondire
Ecco i primi 2 computer di Nvidia per l’intelligenza artificiale a casa: PC che sono supercomputer personali
Un PC con un processore recente (tipo Intel i7 o AMD Ryzen 7), almeno 16 GB di RAM e una scheda grafica NVIDIA (minimo 8 GB di VRAM) fa al caso tuo. Se hai una GPU RTX 3060 o migliore, è un sogno – grazie a CUDA, tutto viene accelerato.
Nota che una GPU non è obbligatoria, ma è fortemente raccomandata per ottenere prestazioni interattive. Per gli LLM, la memoria video (VRAM) è fondamentale: deve essere in grado di contenere almeno una parte dei parametri del modello. Anche la dimensione della finestra di contesto (memoria della conversazione) dipende dalla VRAM disponibile… ecco perché 8 GB di VRAM è il minimo richiesto. In pratica: un modello Llama 7B in 4 bit consuma ~4 GB di VRAM, un 13B ~8 GB, un 30B ~16 GB, un 70B ~32 GB. D’altronde, anche Nvidia per il suo strumento Chat With RTX richiede una RTX 30/40 con almeno 8 GB di VRAM e 16 GB di RAM di sistema.
Per approfondire
Quale scheda grafica scegliere? Le migliori GPU di Nvidia e AMD nel 2025
Su Mac, i chip M1/M2 con 16 GB di RAM funzionano bene anche senza GPU dedicata, grazie a ottimizzazioni come Metal. Ovviamente, più hai un chip ARM recente e potente e più hai di memoria unificata… meglio è.

Server europei, un’offerta valida a vita
Scopri le offerte di pCloud: 2, 5 o 10 To di spazio di archiviazione, situati in server europei e senza abbonamento, per 5 persone. Il gestore di password è incluso!
Spazio di archiviazione? Prevedi da 10 a 40 GB su un SSD per i file del modello. Con questo, puoi già far girare un Mistral 7B o un LLaMA 2 13B senza problemi. Si consiglia vivamente un SSD per caricare i modelli in memoria in modo più rapido… Se hai intenzione di provare più modelli, saranno necessari alcune decine di GB di spazio libero.
Installazione di un LLM sulla nostra macchina
Come spiegato sopra, tutto dipende dalle tue necessità, dai tuoi obiettivi e dal tuo livello tecnico.
| Nivello | Obiettivo | Esempi di strumenti |
| 🟢 Principiante | Interfaccia semplice, pronta all’uso | LM Studio, GPT4All, Chat With RTX |
| 🔵 Intermedio | Linea di comando, controllo più preciso | Ollama, Llama.cpp, LocalAI |
| 🔴 Avanzato | Personalizzazione, fine-tuning | Hugging Face Transformers, Text-Generation-WebUI |
Immagino che ora tu sia entusiasta, quindi passiamo alla pratica.
Principiante: interfaccia visuale
L’idea qui è di scaricare un modello e utilizzarlo come un chatbot, senza passare attraverso righe di comando.
LM Studio
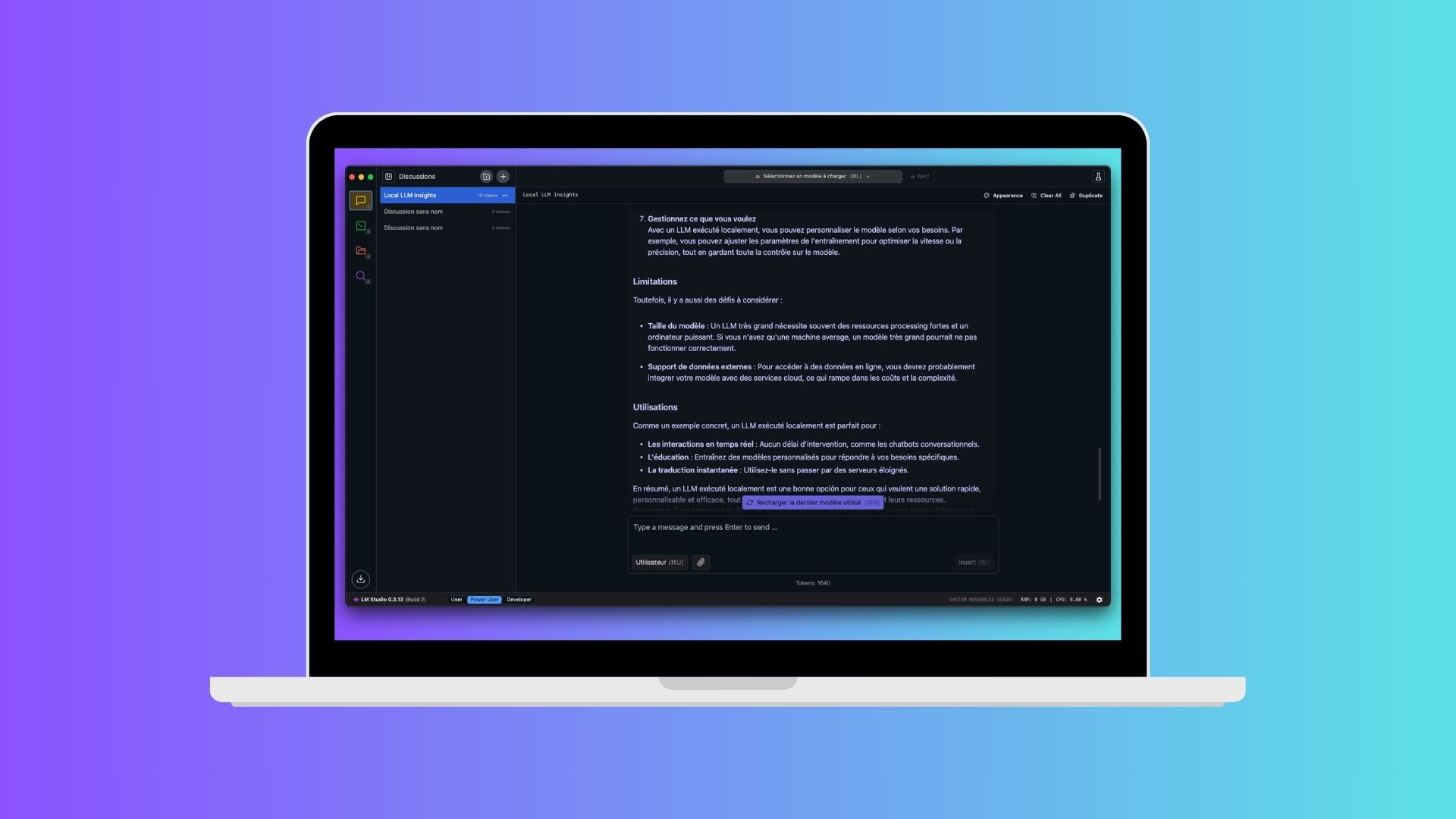
Se cerchi una soluzione pronta all’uso, senza righe di comando, con un’interfaccia piacevole simile a ChatGPT, LM Studio è probabilmente la scelta migliore. Questa applicazione consente di scaricare un modello, avviarlo e dialogare con esso in pochi clic.
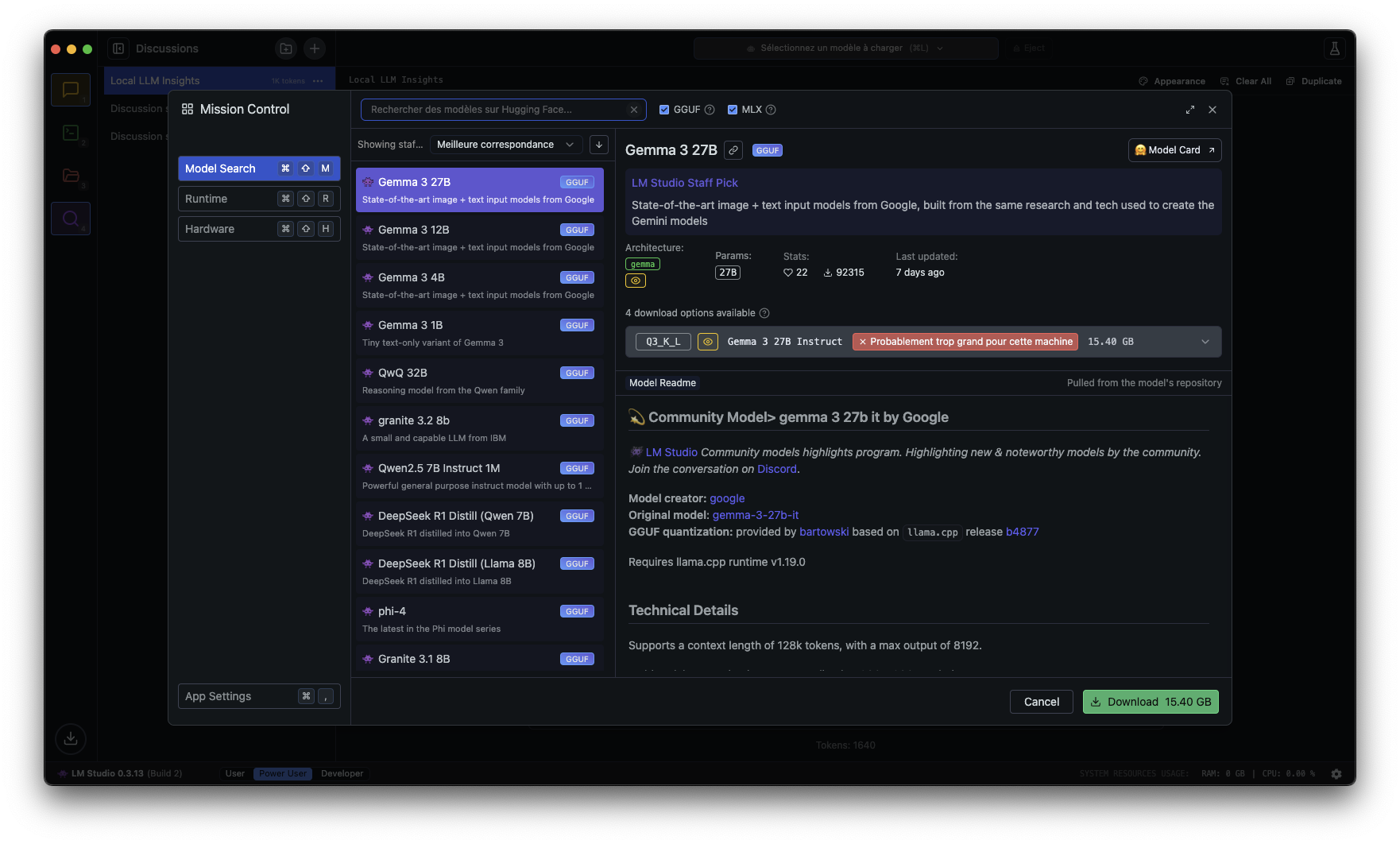
Su Windows, macOS e Linux, l’installazione è rapida. Devi solo andare sul sito ufficiale, lmstudio.ai, scaricare l’installer corrispondente al tuo sistema e eseguirlo.
Su Mac, basta trascinare l’applicazione nella cartella Applicazioni. Su Windows, esegui il file eseguibile e segui i passaggi classici di installazione. Una volta aperto LM Studio, l’interfaccia ti propone di cercare un modello di linguaggio. Una sezione dedicata visualizza i modelli disponibili, con descrizioni e raccomandazioni. Per un buon equilibrio tra prestazioni e qualità delle risposte, Mistral 7B è un ottimo punto di partenza. Pesa solo pochi GB e funziona bene sulla maggior parte delle macchine recenti.
Una volta scaricato il tuo modello, vai alla scheda “Chat”. Puoi digitare qualsiasi domanda e l’IA risponderà immediatamente, localmente, senza passare per un server remoto. Se vuoi approfondire, LM Studio permette di regolare parametri come la lunghezza della risposta, la creatività del modello o la gestione della memoria conversazionale.
GPT4All
Se desideri un’alternativa, GPT4All offre un approccio simile. La sua interfaccia è un po’ più rudimentale ma rimane semplice da usare. Anche in questo caso, puoi scaricare modelli open-source come Llama 2 o DeepSeek e utilizzarli localmente con un’interfaccia di chat intuitiva.
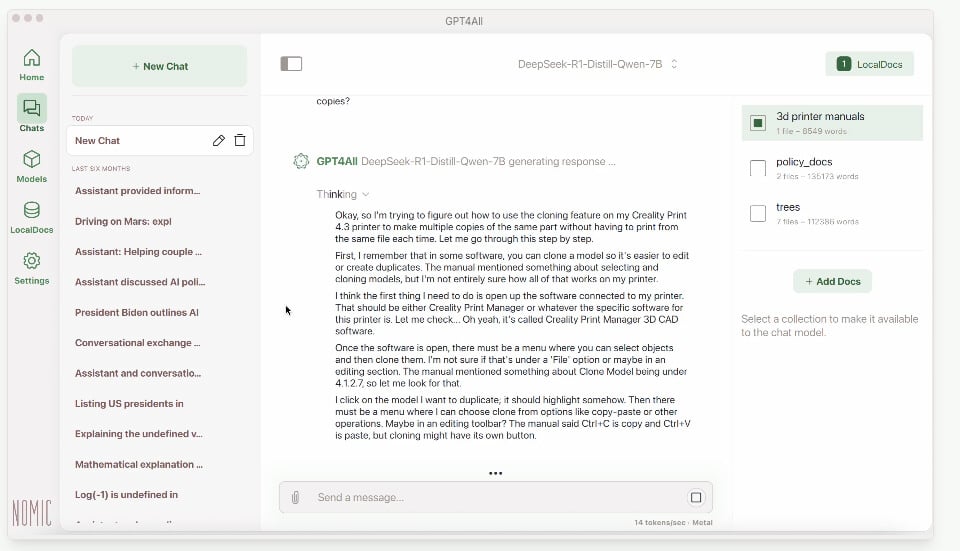
L’installazione è altrettanto facile: basta scaricare l’applicazione da gpt4all.io, installarla e poi scegliere un modello per iniziare a dialogare.
Chat with RTX
Se hai una scheda grafica NVIDIA RTX, puoi anche provare Chat With RTX, una soluzione offerta direttamente da NVIDIA.
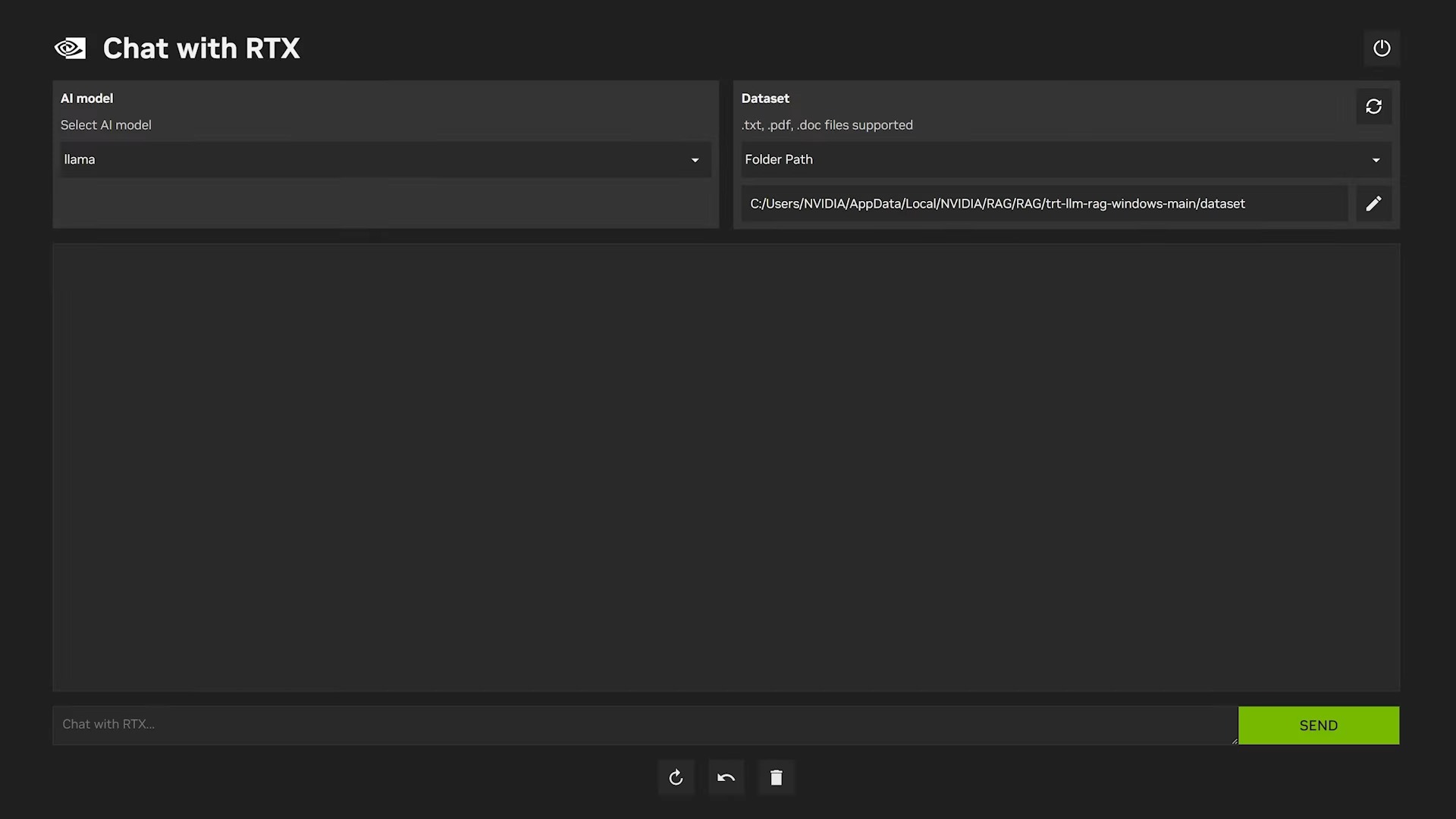
È particolarmente ottimizzata per sfruttare i GPU RTX e consente di eseguire modelli come Llama 2 o Mistral 7B con una fluidità impressionante. Il download avviene dal sito ufficiale di Nvidia e l’installazione è semplice come quella di un videogioco. L’applicazione offre un’interfaccia pulita in cui puoi testare direttamente il modello e vedere le prestazioni offerte dalla tua GPU.
Intermedio: righe di comando e polivalenza
Se desideri un maggiore controllo sul funzionamento del modello, eseguirlo tramite la linea di comando è un’ottima opzione.
Ollama
Ti consente di gestire i modelli in modo più dettagliato, ottimizzare il loro funzionamento e persino chiamarli da altre applicazioni. La soluzione più accessibile per utilizzare un LLM tramite la linea di comando, senza troppe complessità, è Ollama.
Su Mac e GNU/Linux, l’installazione è particolarmente semplice grazie a Homebrew. Basta un solo comando nel terminale: winget install Ollama oppure curl -fsSL https://ollama.ai/install.sh | sh.
Una volta installato, l’uso è altrettanto semplice. Per scaricare e eseguire un modello, basta digitare nel terminale: ollama run mistral… Il modello verrà scaricato automaticamente e avviato in pochi secondi. Puoi ora fargli qualsiasi domanda, direttamente dalla linea di comando.
Se desideri un controllo ancora più preciso sui modelli, Llama.cpp è un’alternativa più tecnica, ma ultra performante. Funziona su tutte le piattaforme e permette di ottimizzare l’esecuzione dei modelli in base all’hardware disponibile. L’installazione richiede alcuni passaggi aggiuntivi.
Llama.cpp è particolarmente utile se desideri sperimentare diversi livelli di quantizzazione, cioè ridurre la dimensione in memoria del modello comprimendo alcuni calcoli per migliorarne le prestazioni. È un ottimo strumento per ottenere prestazioni migliori su macchine modeste, mantenendo comunque un buon livello di qualità delle risposte.
Utilizzare un LLM tramite la linea di comando ti consente inoltre di accedere a integrazioni più flessibili. Puoi, ad esempio, collegare Ollama o Llama.cpp a uno script Python, oppure utilizzarli in modalità server per interagire con un’API locale. È un ottimo modo per avere un assistente IA più potente e adattabile rispetto a quanto offre un’interfaccia grafica standard.
Se desideri integrare un LLM in un sito web, ecco come esporre Ollama come API locale: ollama serve… Questo apre un’API compatibile con OpenAI su http://localhost:11434. Ora puoi interagire con il tuo LLM direttamente da una pagina web, in locale, senza dipendenze esterne.
LocalAI
Se cerchi una soluzione più versatile che non si limiti alla generazione di testi, LocalAI è un’ottima scelta. A differenza di strumenti come LM Studio o GPT4All, che si concentrano sugli LLM, LocalAI è progettato come un’alternativa open-source alle API di OpenAI. Consente non solo di eseguire modelli di linguaggio, ma anche di gestire funzionalità avanzate come la trascrizione audio, la generazione di immagini, e l’integrazione con database vettoriali.
L’installazione è piuttosto semplice e funziona su Windows, macOS e Linux. Su una macchina Linux o Mac, possiamo installarlo tramite Docker per evitare di dover configurare manualmente le dipendenze. Una sola riga è sufficiente per avviare un server LocalAI pronto all’uso, tutto è ben documentato.
Una volta avviato, LocalAI offre un’API compatibile al 100% con OpenAI, il che significa che tutte le applicazioni che utilizzano richieste OpenAI (come l’API di ChatGPT) possono essere reindirizzate al tuo server locale. Puoi quindi aggiungere modelli scaricandoli direttamente da Hugging Face o utilizzando backend come llama.cpp per i modelli di testo, whisper.cpp per la trascrizione audio, o Stable Diffusion per la generazione di immagini.
Se ti senti a tuo agio con la linea di comando e cerchi una soluzione che vada ben oltre un semplice chatbot, LocalAI è uno strumento potente che merita di essere provato. Combinando modelli di testo, riconoscimento vocale, generazione di immagini e embeddings, trasforma il tuo computer in un vero assistente IA locale, in grado di elaborare diversi tipi di dati senza mai inviare una richiesta su Internet.
Avanzato: personalizzazione e fine-tuning
Se vuoi andare ancora più lontano, è possibile personalizzare il tuo modello e persino addestrarlo sui tuoi dati. Per fare ciò, lo strumento di riferimento è Hugging Face Transformers. Questa libreria open-source permette di scaricare, eseguire, modificare e addestrare modelli in modo ultra flessibile.
L’installazione è relativamente semplice. Su Windows, macOS e Linux, basta installare le librerie necessarie con pip: pip install torch transformers accelerate.
Successivamente, le cose si complicherebbero, poiché devi utilizzare uno script Python per caricare il modello e generare testo… Il vantaggio di questo approccio è che puoi modificare gli iperparametri, raffinare le risposte e testare facilmente più modelli.
Se desideri personalizzare un modello con i tuoi dati, puoi utilizzare QLoRA, una tecnica che permette di fine-tuning di un LLM senza richiedere una potenza di calcolo elevata. Questo ti consente, ad esempio, di specializzare un modello in un dominio specifico (finanza, diritto, salute). Ma tra di noi, se sei arrivato fin qui, non hai bisogno di noi.
Esempio con un Mac mini M4
Se parti da zero, nessun problema. Con l’arrivo del Mac mini M4, Apple ha spinto ulteriormente le prestazioni dei suoi chip Apple Silicon.
Con il suo prezzo contenuto, questa macchina è una piattaforma ideale per eseguire modelli di linguaggio locali, effettuare trascrizioni audio in tempo reale, e persino generare immagini e video IA con prestazioni impressionanti.

Un Mac mini M4 con 16 GB di RAM può gestire modelli 7B a 13B senza difficoltà. Un modello come Mistral 7B, ottimizzato per Metal e il GPU Apple, offre risposte istantanee con un minimo consumo energetico. Personalmente, utilizzo DeepSeek R1 Distilled (Qwen 7B).
Puoi facilmente usare LM Studio o Ollama per interagire localmente con l’IA, senza passare per il cloud. Se lavori nella scrittura, programmazione o analisi dei dati, il Mac mini diventa un assistente personale ultra-performante, capace di generare contenuti, riassumere documenti e persino analizzare PDF direttamente da un modello open-source.
Su un Mac mini M4, Ollama sfrutta queste ottimizzazioni e permette di generare testo a una velocità di 10-15 token/secondo su un modello 7B, quindi anche meglio di un ChatGPT gratuito.
Con 24 o 32 GB di RAM o più, il Mac mini M4 può gestire modelli più pesanti come Llama 2 13B a piena precisione, o anche modelli da 30B in versione ottimizzata. Questo ti consente di avere risposte più dettagliate e precise, rimanendo in un ambiente 100% locale. Se lavori nella ricerca o data science, puoi addestrare modelli più piccoli, affinarli con QLoRA e eseguirli direttamente sul tuo Mac senza passare per un server remoto.
Quindi, ci proviamo?
Hai capito, eseguire un LLM su un computer personale è un progetto del tutto realizzabile nel 2025, anche per un utente non esperto, grazie ai progressi dei modelli open-source e degli strumenti di installazione semplificati.
L’IA generativa non è più riservata ai data center: ognuno può ora avere il suo “ChatGPT personale” che gira sul proprio PC, purché dedichi un po’ di tempo e risorse
Fonte: www.frandroid.com
 ABBONATI A CHAT GPT4
ABBONATI A CHAT GPT4
